
Data Architecture: How to Prepare Your Data for AI
AI isn’t struggling because organizations lack data or modern platforms. It’s struggling because most data architectures were never built for the demands AI introduces. Too often, data architecture shows up downstream, after data has already been captured poorly, distorted by workarounds, or lost across handoffs, and teams end up stuck in the same loop of building new platforms, pipelines, dashboards, and AI experiments, only to spend months “fixing the data” again. In brief, AI doesn’t just need more data. It needs operationally accurate, consistently defined, traceable, and secure data, created correctly at the source, not patched together at the end.
1. The Problem of Data Architecture
A lot of “data architecture” work still happens too far downstream, after the data has already been created, captured poorly, distorted by workarounds, or lost in handoffs. By the time the data team is modelling it in a warehouse or cleaning it in a lakehouse, the core issues are already baked in.
That’s why so many organizations get stuck in the same loop: they stand up a new platform, build new pipelines, add new dashboards, and launch fresh AI experiments, only to spend the next several months “fixing the data” all over again[i].
The real problem isn’t a lack of data tools. It’s that data architecture is often treated as a reporting layer concern, instead of what it actually is: the architecture of enterprise truth.
If your team wants to prepare for AI, you have to stop thinking of data as something that gets “prepared later.” Data needs to be created at the source, in processes like onboarding, claims, fulfilment, service, finance, procurement, where user inputs, validation rules, IDs, workflow states, exceptions, timestamps, and reference data get defined (or ignored).
AI will punish you for every upstream shortcut you’ve made, like missing mandatory fields, inconsistent identifiers, unclear state transitions, and gaps created by manual workarounds. It will also expose silent system failures and “tribal knowledge” business rules that only exist in people’s heads.
AI doesn’t just need “data.” It needs operationally accurate data, built from the first click onward—not patched together at the final dashboard.
2. Define “AI-Ready Data”
“AI-ready data” is not a buzzword. It’s a practical standard: data that can be trusted and used repeatedly for AI workloads without heroic effort. AI-ready data is typically:
-
Accurate enough for the decisions being automated or augmented
-
Complete enough to represent the process end-to-end
-
Consistently defined across domains (same entity ≠ three definitions)
-
Timely (with known latency, not random delays)
-
Traceable (lineage + transformations + sources)
-
Secure (protected and access-controlled through its lifecycle)
-
Context-rich (metadata, meaning, units, thresholds, caveats)
3. What usually breaks first
In practice, most AI initiatives don’t fail because the model is weak. They fail because these four data problems surface immediately once AI hits real-world conditions:
a- Definitions collapse under pressure. Most organizations don’t have one definition of “customer,” “active,” “risk,” “order complete,” or “churn.” AI forces those inconsistencies into the open quickly.
b- Quality issues become model issues. In analytics, low-quality data creates confusing dashboards. In AI, low-quality data creates confident, wrong answers. That’s worse.
c- Lineage can’t explain outcomes. AI outputs get challenged. If you can’t trace back inputs and transformations, trust dies, adoption stalls, and governance shuts things down.
d- Data access becomes uncontrolled. As soon as teams start fine-tuning models, building RAG search, or experimenting with agents, they begin pulling data from everywhere. Without clear boundaries, you get accidental exposure of sensitive data and compliance risk.
AI-ready data isn’t about perfection. It’s about repeatability, traceability, and safety.
4. Design Data Products, Not Data Pipelines
A common trap is building AI readiness as “more pipelines.” The result is predictable: duplicated logic, inconsistent transformations, and data that nobody truly owns. A better approach is shifting to data products.
a- What is a data product?
A data product is a curated, reusable, trustworthy dataset (or dataset family) with:
-
a clear business purpose
-
an accountable owner
-
documented definitions and semantics
-
measurable quality expectations
-
guaranteed availability and refresh patterns
-
built-in access controls
-
discoverability via catalog/metadata
Pipelines are plumbing. Data products are what the business and AI teams actually consume.
b- Why this matters for AI?
AI isn’t one workload. It’s many, spanning everything from model training datasets and feature sets to embeddings for RAG, real-time decisioning inputs, and ongoing monitoring, drift detection, and feedback loops.
If every AI initiative creates its own “special dataset,” chaos follows, with multiple versions of the truth, duplicated transformation logic, inconsistent KPIs, and expensive remediation. The result is predictable: low trust in the outputs and slow, fragile AI delivery.
Data products solve this by creating stable “contracts” that other teams can build on.
c- Examples of high-leverage data products
To make AI delivery faster and more reliable, focus on building a small set of high-leverage data products that can be reused across multiple teams and use cases, such as:
-
Customer Identity + Profile (golden ID, hierarchy, contractability, consent)
-
Order Lifecycle Events (placed → processed → shipped → delivered → returned)
-
Product Master + Classification (attributes, lifecycle, mapping to channels)
-
Operational Exceptions Log (failures, retries, fallbacks, manual overrides)
-
Financial Transaction Ledger Extract (auditable movements and balances)
If you build data products well, AI teams stop wasting time preparing data and start delivering outcomes.
5. Build for Quality, Observability, and Trust
If you want AI to work in production, quality cannot be a cleanup exercise. It must be engineered, monitored, and continuously improved, because AI systems are sensitive to small changes and silently degrade when inputs drift.
a- Data quality for AI is not the same as BI quality
With BI, you can sometimes tolerate “mostly right.” With AI, “mostly right” creates bad generalization, unstable predictions, or unreliable generated outputs. To prepare your data for AI, you need quality at three levels:
Structural quality (schema and shape)
-
Missing or unexpected fields
-
Broken types (string vs numeric, date parsing failures)
-
Null spikes where they shouldn’t exist
-
Schema drift is breaking downstream logic
Business quality (rules that reflect reality)
-
Invalid workflow states
-
Impossible values (negative quantity, invalid status transitions)
-
Duplicate entities where uniqueness should exist
-
Totals not matching line items
-
Reference data mismatches
Statistical quality (drift and behavioural change)
Statistical quality is what teams most often miss: the data can still be technically “valid,” but its behavior shifts in ways that quietly destabilize AI. When average order value suddenly changes, new customer segments appear, product mix shifts, sensor readings trend differently, or claims spike, models can drift and predictions become unreliable. That’s not just a data problem. It’s an AI stability problem.
b- Observability: detect problems before users do
Data observability means you can answer these questions quickly:
-
What changed?
-
When did it change?
-
What assets did it impact downstream?
-
Is this a one-off incident or a systemic failure?
-
Who owns the fix?
Without observability, AI delivery turns into a predictable cycle from Deploy, Degrade, Firefight, Patch, to Repeat.
c- Trust is built through traceability
Trust is built through traceability. You can’t ask the business to rely on AI if you can’t prove where the input data came from, what transformations were applied, and which dataset version was used. Just as importantly, teams need visibility into who approved access and what quality checks passed or failed. AI success isn’t just model performance. It’s organizational confidence in the system.
6. Modernize Integration: Batch, Streaming, and APIs Together
AI increases the variety of data access patterns you need. A purely batch-based architecture is too slow for many AI use cases, but “everything streaming” is expensive and unnecessary. An AI-ready integration architecture supports multiple modes without creating conflicting versions of reality.
a- Batch: still essential
Batch is still essential for historical training datasets, cost-efficient transformations, periodic reconciliation and governance reporting, and large aggregations or scoring runs, but while it’s not outdated, it’s not enough on its own.
b- Streaming: where AI meets operations
Streaming matters when AI decisions are time-sensitive, like fraud detection, real-time personalization, predictive maintenance, supply chain sensing, and anomaly detection, because the value of the insight depends on acting immediately, not hours later. In these scenarios, streaming isn’t a “nice to have”; it’s what makes operational AI possible.
But streaming also introduces architectural requirements many teams underestimate, including event versioning, idempotency, replay capability, ordering and deduplication, and dead-letter queues with robust retry handling. Without these controls, streaming pipelines become fragile, hard to debug, and unreliable for AI workloads that depend on consistent, trustworthy signals.
Without those, “real-time AI” becomes “real-time confusion.”
c- APIs: curated operational consumption
APIs are how you turn core enterprise data into a reliable capability for apps, analytics, AI services, and increasingly, agents and orchestration workflows. Instead of every team extracting and reshaping data differently, building an API strategy provides a consistent, reusable way to access what the business actually runs on.
They also create a crucial control point for consistent definitions, access enforcement, rate limiting, and protection, and embedding domain rules close to the source. The goal isn’t to standardize everything on one integration style. It’s to unify semantics, not technologies.
Most AI programs fail because they end up with three disconnected worlds. Batch data says one thing, streaming data says another, and API data says something else. So teams spend more time reconciling contradictions than building real capabilities. The architecture goal is one shared truth, delivered through multiple latency patterns without changing the underlying meaning.
A practical move here is formalizing recognized business events. This makes integration and AI development dramatically simpler because everyone is working from the same operational language.
7. Data Governance That Enables AI Instead of Slowing It Down
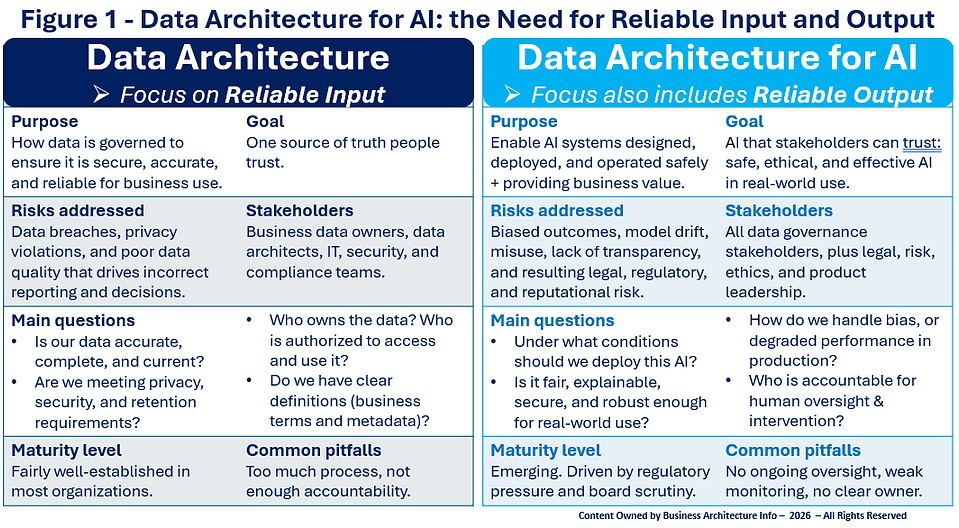
This is where many organizations get it wrong: they treat governance as paperwork. But AI increases the blast radius of mistakes, so governance must be real, while still allowing teams to move. The key mindset shift for data governance is not only to focus on the reliability of inputs, but also on trustworthy outcomes, as shown in Figure 1 above.
-
Data governance used to focus mostly on reliable inputs.
-
Data governance for AI also needs to focus on reliable outcomes.
a- What data governance should enforce (inputs)
Data architects involved in governance at a minimum need to ask themselves the following:
-
Is the data accurate, complete, and up to date?
-
Who owns it? Who can access it?
-
Are we compliant with privacy, retention, and security rules?
If these inputs are broken, AI is dead on arrival.
b- What data governance for AI must also address (outcomes)
Data governance for AI must also expand its scope by finding answers to these questions:
-
Should we deploy this AI at all, and in what context?
-
Is it fair, explainable, robust, and safe?
-
How do we handle bias, drift, and degraded performance in production?
-
Who is accountable for oversight and human intervention?
This is why Data governance for AI pulls in more stakeholders: legal, risk, ethics, product leadership, and not just data roles.
c- Governance that helps instead of blocks
If governance is designed as a one-time approval gate, teams will route around it, so AI-ready governance must be continuous, automated where possible, embedded into the architecture, and measurable and auditable.
That means building governance mechanisms like:
-
classification and policy tagging on datasets
-
role-based access control tied to business roles
-
approved-use boundaries for model training and retrieval
-
lineage visibility from source → feature → model outcome
-
monitoring requirements for drift and harmful outputs
-
clear accountability for interventions and shutdowns
d- The hard truth: governance failures will become AI failures
The hard truth is that governance failures will become AI failures. If you don’t govern data properly, you risk breaches and bad decisions, and if you don’t govern AI properly, you risk harmful outcomes, reputational damage, and regulatory exposure. The goal isn’t “more control”. It’s finding a safe speed, where teams can build AI quickly and responsibly because the architecture enforces the rules by default.
Preparing your data for AI isn’t about chasing the next shiny tool or launching yet another modernization project. It’s about rebuilding the foundations that make data trustworthy, reusable, and safe at scale. That means defining what AI-ready data really looks like, shifting from pipelines to data products, engineering quality and observability into daily operations, supporting multiple integration patterns without breaking semantic consistency, and implementing governance that enables responsible speed rather than blocking progress. Because in the end, AI success isn’t just model performance. It’s the organization’s confidence that the data and decisions behind it can be trusted.
________________________________
[i] Read more about this subject in this article entitled “Today’s Data Architect: Too Narrow, Too Late, and Nowhere Near the Data That Matters,” written in December 2025 by V. Prabhakar.